IK分词器的安装与使用
前言
ES默认的分词器对中文分词并不友好,所以我们一般会安装中文分词插件,以便能更好的支持中文分词检索。
而ES的中文分词器中,最流行的必然是IK分词器。
一、IK分词器介绍
IK分词器在是一款基于词典和规则的中文分词器。这里讲解的IK分词器是独立于Elasticsearch、Lucene、Solr,可以直接用在java代码中的部分。实际工作中IK分词器一般都是集成到Solr和Elasticsearch搜索引擎里面使用。
IK分词采用Java编写。
IK分词的效果主要取决于词库,目前自带主词典拥有27万左右的汉语单词量。对于应用领域的不同,需要各类专业词库的支持。词库还可以自己维护。
IK分词器地址:https://github.com/medcl/elasticsearch-analysis-ik
IK分词器有两种分词模式:ik_max_word和ik_smart
二、IK分词器安装
1、离线安装
- 下载预编译的安装包,下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
IK分词器版本和ES版本的匹配关系: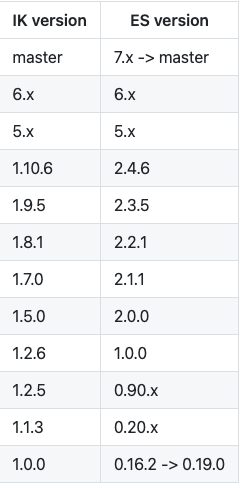
- 创建创建目录
cd $ES_HOME/plugins/ && mkdir ik- 解压安装包
将下载的预编译包解压到新建的目录中
cp elasticsearch-analysis-ik-7.13.0.zip $ES_HOME/plugins/ik cd $ES_HOME/plugins/ik unzip elasticsearch-analysis-ik-7.13.0.zip2、install在线安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.13.0/elasticsearch-analysis-ik-7.13.0.zip三、分词模式
IK分词器有两种分词模式:
1.细粒度模式 ik_max_word
2.智能模式 ik_smart
2种模式的分词演示:
细粒度模式
采用细粒度模式ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,华,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合。
POST _analyze { "text": ["中华人民共和国国歌"], "analyzer": "ik_max_word" }执行结果:
{
"tokens": [{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "中华人民",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "华人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
},
{
"token": "人民共和国",
"start_offset": 2,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
},
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 7
},
{
"token": "国",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 8
},
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 9
}
]
}分词规则:
- 当查询词在词典中不存在时,会按字拆分
例如:在北–>在,北 - 当查询词在词典中存在,且长度为两个字时,有时拆分有时不拆分
例如:甲乙–>甲乙 , 联通–>联通,联,通 - 当查询词在词典中存在,且查询词的一部分也在词典在中存在,则分别拆分
例如:甲乙丙丁–>甲乙丙丁,甲乙,丙丁 中国联通–>中国联通,中国,国联,联通,通 - 当查询词任意部分都不在词典中存储,则按字拆分
智能模式
智能模式ik_smart会做最粗粒度的拆分。比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
POST _analyze { "text": ["中华人民共和国国歌"], "analyzer": "ik_smart" }执行结果:
{ "tokens" : [ { "token" : "中华人民共和国", "start_offset" : 0, "end_offset" : 7, "type" : "CN_WORD", "position" : 0 }, { "token" : "国歌", "start_offset" : 7, "end_offset" : 9, "type" : "CN_WORD", "position" : 1 } ] }分词规则:
- 当查询词在词典中不存在时,会按字拆分
例如:在北–>在,北 - 当查询词在词典中存在,不做拆分
例如:甲乙–>甲乙,甲乙丙丁–>甲乙丙丁 - 当查询词任意部分都不在词典中存储,则按字拆分
最佳实践:
依据上述规律,我们可以在写入数据时使用ik_max_word,增加分词数量,提高被命中几率,在查询数据时使用ik_smart,减少分词数量,提升结果准确率,减少无关结果
四、IK分词器实战
1、创建索引
说明:创建索引my-index-000001,字段content的类型为text。所以在数据写入时会进行分词存储。
通过analyzer属性指定写入分词器采用细粒度模式ik_max_word;通过search_analyzer属性指定查询时采用智能模式ik_smart
PUT my-index-000001 { "mappings": { "properties": { "content": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" } } } }2、添加数据
PUT my-index-000001/_doc/1 { "content": "美国留给伊拉克的是个烂摊子吗" } PUT my-index-000001/_doc/2 { "content": "公安部:各地校车将享最高路权" } PUT my-index-000001/_doc/3 { "content": "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船" } PUT my-index-000001/_doc/4 { "content": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首" }3、全文检索查询
GET my-index-000001/_search { "query": { "match": { "content": "中国" } }, "highlight" : { "fields" : { "content" : {} } } }查询结果:
"hits" : { "total" : { "value" : 2, "relation" : "eq" }, "max_score" : 0.63013375, "hits" : [ { "_index" : "my-index-000001", "_type" : "_doc", "_id" : "3", "_score" : 0.63013375, "_source" : { "content" : "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船" }, "highlight" : { "content" : [ "中韩渔警冲突调查:韩警平均每天扣1艘<em>中国</em>渔船" ] } }, { "_index" : "my-index-000001", "_type" : "_doc", "_id" : "4", "_score" : 0.63013375, "_source" : { "content" : "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首" }, "highlight" : { "content" : [ "<em>中国</em>驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首" ] } } ] }五、词典配置
很多时候默认的分词效果达不到线上使用的要求,这就需要不断维护扩展词典和停止词字典,提高分词匹配的准确性,优化用户体验。
在IK分词器中,主要可以维护2种词典,一种是扩展词典,可以自定义一些词语,提高分词精读。
另一种是停止词词典,停止词就是指不会被分词拆分出来的词语,不参与分词和检索操作。
可以通过修改IKAnalyzer.cfg.xml配置文件,来自定义词典。
IKAnalyzer.cfg.xml的位置为{plugins}/elasticsearch-analysis-ik-*/config/。
其中以dic结尾的文件都是词典。
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典,可以配置多个词典--> <entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">custom/ext_stopword.dic</entry> <!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">location</entry> <!--用户可以在这里配置远程扩展停止词字典--> <entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry> </properties>注意⚠️:
直接修改ext_dict属性中配置的字段里面的内容,并不能立刻生效。只有重启ES进程实例,修改的内容才会生效。
而通过远程扩展的字典,可以实现词典的热更新,不用重启ES进程实例。
六、热更新词典
目前该插件支持热更新 IK 分词,通过上文在 IK 配置文件中提到的如下配置
<!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">location</entry> <!--用户可以在这里配置远程扩展停止词字典--> <entry key="remote_ext_stopwords">location</entry>其中 location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
该 http 请求需要返回两个头部(header),一个是 Last-Modified,一个是 ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
该 http 请求返回的内容格式是一行一个分词,换行符用 \n 即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
1、配置Nginx
设置Nginx的监听端口为8999,并且新增/getRemoteDic路径的location,用于读取IK分词器中配置的字典信息。
server { listen 8999; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; } #新增/getRemoteDic路径,用于读取字段 location /getRemoteDic { alias /usr/local/src/elasticsearch-7.10.2/plugins/analysis-ik/config; autoindex on; } ……访问{ip}:8999/getRemoteDic能够看到字典文件信息,说明访问路径配置成功。
2、新建扩展字典
新建扩展词典ext_my.dic
vi ext_my.dic 宜尚 宜尚智能家具 帆软新建扩展停止词词典my_stopword.dic
vi my_stopword.dic 有限公司 有限 公司3、配置IK远程字典
<properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">http://192.168.100.241:8999/getRemoteDic/ext_my.dic</entry> <!--用户可以在这里配置远程扩展停止词字典--> <entry key="remote_ext_stopwords">http://192.168.100.241:8999/getRemoteDic/my_stopword.dic</entry> </properties>4、重启ES进程
在启动日志中,看见日志,说明扩展字段信息被正确加载。
5、验证字典效果
POST _analyze { "text": ["宜尚科技有限公司"], "analyzer": "ik_max_word" }执行结果:
{ "tokens" : [ { "token" : "宜尚", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "科技", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 } ] }“宜尚”作为扩展词典中的词,被正确分词,而没有拆分成单个的字。
“有限公司”由于是扩展的停止词词典中的词,被排除在分词结果中。
说明扩展词典和停止词词典均生效了。
6、验证热加载
默认情况,“字节跳动”在ik_smart智能模式下,会被拆分成“字节”和“跳动”两个词。
POST _analyze { "text": ["字节跳动有限公司"], "analyzer": "ik_smart" } { "tokens" : [ { "token" : "字节", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "跳动", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 } ] }修改词典ext_my.dic,新增“字节跳动”
vi ext_my.dic 宜尚 宜尚智能家具 帆软 字节跳动ES会根据一定频率,重新加载远程字典信息。(这里我们没有执行ES进程重启操作,但是扩展的字典信息自动被重新加载)
重新尝试分词解析,”字节跳动”没有被继续拆分,说明热更新词典生效。
{ "tokens" : [ { "token" : "字节跳动", "start_offset" : 0, "end_offset" : 4, "type" : "CN_WORD", "position" : 0 } ] }