浅谈ES全文检索搜索结果优化
序言
最近做了一个网盘资源搜索引擎,使用ES的全文检索功能时发现搜索结果总是差强人意。正确的数据往往排名非常靠后,靠前的都是一些相似度极低的记录。
最先考虑的是分词的原因,但是词库更新频率不好把控暂时搁置了,今天从搜索条件入手开始进行搜索的优化
搜索结果优化
优化结果
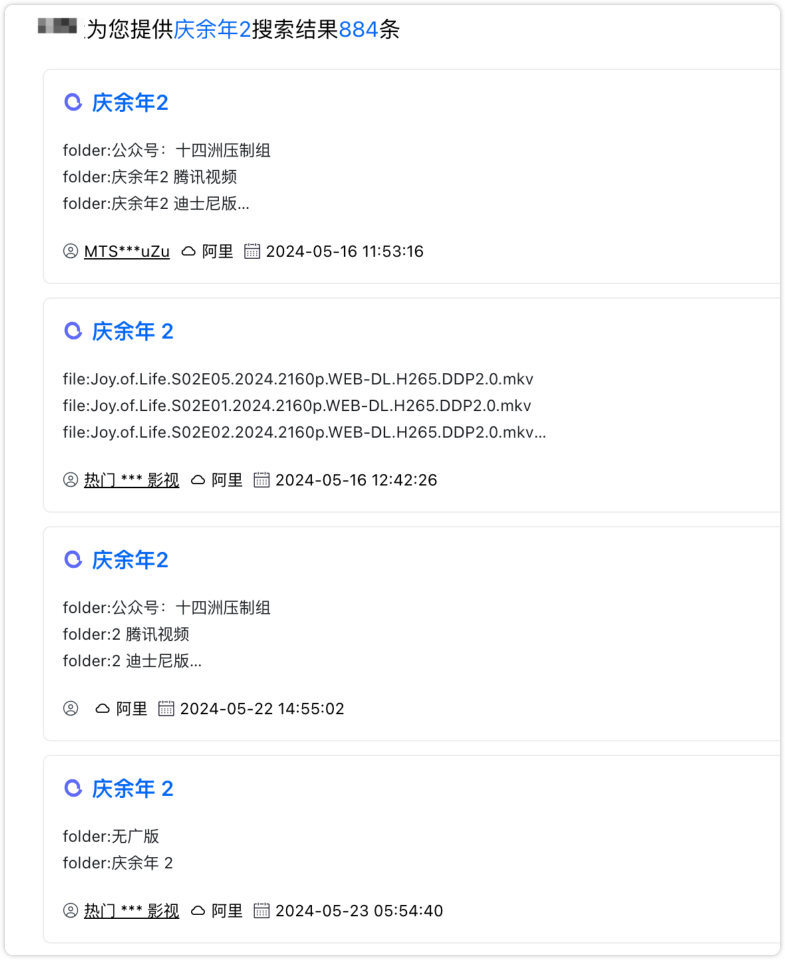
开头先来一张优化结果对比
优化前

优化后
过程
背景
同众多小白玩家一样,我对于ES并没有什么深入的研究。搭建ES服务,接入ES服务,这通常就是我们的日常使用了。
索引结构如下
"_source" : {
"id" : 21,
"disk_type" : 1,
"disk_name" : "【美剧】德黑兰.全2季",
"disk_id" : "",
"disk_pwd" : "",
"doc_id" : "c462c23807ab2659f82fc4567da4cd68",
"extensions" : "全2季",
"share_user" : "二狗*",
"share_time" : "2024-04-30 15:23:10",
"files" : """folder:德黑兰S02
folder:德黑兰S01
folder:【美剧】德黑兰.全2季""",
"is_main" : 0,
"weight" : 1,
"enabled" : 1,
"status" : 1,
"es" : 0,
"created_at" : "2024-04-30 15:23:10",
"updated_at" : "2024-04-30 15:23:10"
}1. 最初的搜索
当我们构建完文档之后,最简单的全文检索方式就是match
这里我使用了multi_match来进行多字段的匹配检索
这样使用非常方便和快捷,而且实现了全文检索的需求
但是搜索结果并不符合预期
"query":{
"multi_match": {
"query":"庆余年2",
"fields": [
"disk_name","files"
}2. 使用bool优化搜索
实现这个功能就使用了bool的查询过滤器
bool 查询中提供了4个语句,must / filter / should / must_not
filter / must_not属于过滤器must / should属于查询器
对于过滤器,我们只需要知道以下两点:
- 过滤器并不计算相关性评分,因为被过滤掉的内容不会影响返回内容的排序;
- 过滤器可以使用 ES 内部的缓存,所以过滤器可以提高查询速度。
需要注意的是:虽然
must查询像是一种正向过滤器,但是它所查询的结果将会返回并会和其他的查询一起计算相关性评分,因此无法使用缓存,与过滤器并不一样。
{
"query": {
"bool": {
"should": [
{
"match": {
"disk_aname": "庆余年2"
}
},
{
"match": {
"files": "庆余年2"
}
}
],
"filter": [
{
"term": {
"status": 1
}
}
]
}
}
}3. 使用 match_phrase 提高搜索短语权重
通过上面的优化,我们搜索结果的呈现已经有了初步的改善
但是与我们的预期仍旧有一定的出入,我们会看到搜索的结果和搜索关键词不是连续匹配的情况,而用户想要匹配整个短语的记录却排在后面
首先需要明白,这并不是ES的Bug
在了解这种情况之前,我们需要先弄清楚ES是如何处理match的
首先 multi_match 会把多个字段的匹配转换成多个 match 查询组合并分别对字段进行 match 查询match 执行查询时,会先把关键词经过 search_analyzer 设置的分析器分析
再把分析器得到的结果挨个放进 bool 查询中的 should 语句
这些 should 没有权重与顺序的差别,并且只要命中一个should 语句的文档都会被返回
{
"query":{
"match":{"disk_name":"庆"}
}
}这样就导致了有的文档只拥有查询短语中若干个词,但评分却比可以匹配整个短语的文档高的情况
match_phrase 要求必须命中所有分词,并且返回的文档命中的词也要按照查询短语的顺序,词的间距可以使用 slop 设置。
match_phrase 虽然帮我们解决了顺序的问题,但是它要求比较苛刻,需要命中所有分词。如果单独使用它来进行搜索,会发现搜索出来的结果相比 match 会大大减少,这是因为匹配若干个词的文档和匹配顺序不对的文档都没被返回。
这时候可以采用 bool 查询的 should 语句,同时使用 match 与 match_phrase 查询语句,这样相当于 match_pharse 提高了搜索短语顺序的权重,使得能够顺序匹配到的文档相关性评分更高。
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"disk_name": {
"query": "庆余年2",
"slop": "5"
}
}
},
{
"match": {
"disk_name": {
"query": "庆余年2",
}
}
}
]
}
}
}
4. 使用 boost 调整查询语句的权重
通过以上的优化,我们发现一个显而易见的问题:所有字段没有权重之分
根据我们的需求,disk_name字段的权重应该高于其他的字段
这时候我们可以通过使用boost的配置来增加权重,这里需要注意设置的对象不是某个对象,而是某个查询语句
最终得分 = 默认得分 * boost
几个需要注意的地方:
数据质量高的字段可以相应提高权重;
match_phrase语句的权重应该高于相应字段match查询的权重,因为文档中按顺序匹配的短语可能数量不会太多,但是查询关键词被分词后的词语将会很多,match的得分将会比较高,则match的得分将会冲淡match_phrase的影响;在
mappings设置中,可以针对字段设置权重,查询时不用再针对字段使用boost设置。
{
"query": {
"bool": {
"minimum_should_match": 1,
"should": [
{
"match_phrase": {
"disk_name": {
"query": "庆余年2",
"boost": "100",
"slop": "5"
}
}
},
{
"match": {
"disk_name": {
"query": "庆余年2",
"boost": "20"
}
}
}
]
}
}
}5. 最终结果
到这里,我们的搜索优化就进行的差不多了
现在的搜索结果差不多可以让人满意了
最后,ES 是一个通用型的全文检索引擎
如果想用 ES 搭建一个专业的搜索平台,必须要经过搜索调优才可以达到可用的状态。
本文记录了基于作者的ES搜索优化过程,希望你也可以从中学习到有用的知识。